

from Multigraph project, McGill University (at Interactingwithprint.org)
I’ve been thinking a lot about nanopublications recently. This is a concept primarily discussed in scientific scholarly communication. Nanopub.org explains:
A nanopublication is the smallest unit of publishable information: an assertion about anything that can be uniquely identified and attributed to its author.
With nanopublications, it is possible to disseminate individual data as independent publications with or without an accompanying research article.
Nanopublications can be…machine readable…opening the door to universal interoperability…data to be analyzed for the discovery of new associations that would otherwise be beyond the capacity of human reasoning.
The nanopublishing idea builds on earlier concepts such as microformats, a way to mark elements within pages (or other content) for machine-readability and reusability: for example, contact information, geographic coordinates, calendar events, or citation data.

T. H. Nelson’s “Literary Machines,” a key work in hypertext theory
You might say microformats and nanopublication are simply ways to generalize or extend the “page” model which the World Wide Web and HTML made so remarkably ubiquitous. They point out that it may often be useful to address, describe, and use separate elements within the customary unit of the page or document. More generally, the long tradition of hypertext theory and systems is all about making content more atomicized and networked.
With “nanopublishing,” I’ve been thinking not so much about science and logic/data elements, but about disaggregating books or articles in trade and Humanities/Social Science (HSS) publishing. That is to say, thinking about various ways to pull apart, reassemble books, or their production and use:
- distributing or gathering content fragments while writing (tweet-writing?)
- writing as link assemblage, or curation of elements which also exist independently.
- allowing larger units such as monographs (books) to be used, distributed, commented on, linked down to atomic levels.
Why Do We Care?
In scholarly publishing, we have a noble tradition of rather non-atomicized, non-hypertextual work, in particular the (appropriately-named) monograph, or book-length single-author/editor work.
Monograph publishing is most important in HSS disciplines, and is also, in recent years, a general locus and scene of woe. Research libraries, the primary purchasers of scholarly monographs, have cut their acquisitions budgets (often citing fast-rising costs of science journals and electronic databases as the reason). University presses, the primary publishers of these monographs, have substantially reduced number of titles and print run sizes, even while tenure & promotion decisions in HSS continue to depend heavily on monograph publishing credits. The field is widely regarded as struggling, and part of a crisis in the humanities.
To the death scene of the monograph, therefore, I bring you the multigraph.
Well, really there are many people and projects disaggregating the book these days; I am bringing you a label. Let me explain: in mathematics a graph is an abstract description of objects connected by links, used to rigorously explore pure mathematics and analyze phenomena such as maps or computer programs. Among the types of graph is a multigraph, in which points may be connected more than one way, as in Euler’s graph representation of the multiple bridges connecting either bank to the island.
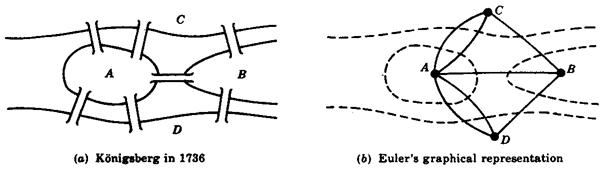
Euler’s multigraph representation of the bridges of Konigsberg
I propose “multigraph” to describe a monograph reconceived as an gathering of many content components, structures, and pathways for creation and use.
All this came up from discussions with people at the OAPEN-UK project, which is running a multi-year experiment to compare Open Access monograph publishing vs. non-OA.

1928 Multigraph Kopierer
In usual awkward-uncle, or perhaps bull-in-the-china-shop fashion, I started to feel impelled to ask some basic, perhaps embarrassing man-off-the-street questions about the HSS monograph. First: why assume that the scholarly monograph must be preserved, if it is widely viewed to be not functioning? (i.e. by Dame Finch, author of the Finch Report for UK’s transition to Open Access). To me it’s remarkable that so many in HSS scholary communications simply take monograph publication as a given or necessity, and ask how a different funding or distribution structure (say Open Access) might address the problems.
This leads to a second, sort of refined version of the inquiry, which starts by asking, what do people actually mean when they say “monograph”? Single-author or -editor, long-form, non-continuing, text, it is normally said. However, it is easily observed that a monograph, like text in general, is not unitary but compound on many levels, whether sentences or sections or chapters. What is really meant by “monograph” is that certain assertions (e.g. editorial authority, copyright) are made, and certain transactions (first sale, licensing) limited to, the compound book level.
Even so, it is familiar for a monograph to contain, say, essays which formerly circulated in serials or are subsequently reprinted/cited separately. Even the “non-continuing” part starts to break down if you consider it has a publisher, genre, and perhaps series which provide elements of ongoing continuity.
So I think one can legitimately ask, to what degree is the monograph just a producer- and marketing-driven information bundling, that may not serve “customers” needs? We might analogize the compound book to the academic journal or music album, a bundling of elements which increasingly operate independently, which may be preferable to both platforms/aggregators (iTunes, Elsevier) and consumers. Related to bundling is padding, i.e. fitting content to a container: in trade publishing, it is often observed that the book form, particularly for non-fiction, is based on marketing traditions rather than the content or readers’ needs.
On the decline and possibilities for rebirth of the monograph, Patrick Dunleavy of LSE, just wrote a good 2-part essay. See part 2: “E-books herald the second coming of books in university social science.” He especially highlights the new marketing and usability affordances of ebooks, as they can be offered in large assemblages, disaggregated into chapters, etc.
1921 Gammeter Multigraph Folder
So with OAPEN-UK my suggestion is to experiment to compare traditional monograph projects with open, incremental, disaggregated-model projects. (“incremental” is meant to suggest the term “incremental building”, the typical developing-world practice of acquiring property and building structures in steps as resources allow). There are some interesting and well-developed models now from U.S. digital humanities, e.g. the MediaCommons Press platform used by Kathleen Fitzpatrick to write/publish “Planned Obsolescence”; or the just-unveiled open-access edition of Debates in the Digital Humanities, edited by Matthew Gold at (now at CUNY Grad Center).
I’m also coming to this from a project in building automatic message/tweet generation from scholarly articles. I have a hunch that a lot of the potential in that may be tweets / nanopubs that extract/highlight specific points, subsections, quotes, claims — as opposed to just attempting to encapsulate a whole paper or book. Of course you might do the latter too, but it may be just one type of representation nanopublication generated from the work.
We might view the “monograph” as simply one state or frame for a large network of activities:
- assemblage and composition of elements by one or more writer/editor/compilers, which might be a mixture of people, processes, machines
- distribution and testing of elements while and after writing
- sharing and reuse of “monograph” components, from quotes to sections, in later stages
Arguably, this is largely what’s already happening, in fits and spurts. I’m suggesting we acknowledge, embrace, and build for it. Distribute the monograph into multigraph, to save it..
———-
See also follow-up post, “The Print-Academic Complex and the New Regime” (January 4, 2013).
Pingback: From Monograph to Multigraph: the Distributed Book | Impact of Social Sciences
Pingback: Open Library of Humanities – further envisioning | Tim McCormick
@digitaldigs imo current monograph practices are largely anachronism, ineffective as communication. Cf. “multigraph” http://t.co/yTAROrnnO8
I agree with your argument here and like the idea of the multigraph. I think we believe that the monograph represents a kind of sustained project and research, but as you point out, that belief is manufactured through rhetorical moves, editorial structures, and the material construction of the book itself. The question then becomes for me to what extent to we value the intellectual synthesis of parts that a monograph represents and how do we recapture that synthesis in the multigraph?
Pingback: Interview: Tim McCormick on Social Media, Scholarly Communication and Digital Publishing, Part 1 - Critical Margins